임계 영역(critical section)을 만들자
- 객체지향언어
전적으로 개발자의 코딩에 의존
변경(mutation)을 하지 말자
- 함수형언어. 대표적으로 erlang
상대적으로 메모리 낭비와 단일 쓰레드 성능 저하 발생
공유(shared)를 하지말자
- Rust
출처 : Rust 나무위키, https://lynlab.co.kr/blog/63
'잡담' 카테고리의 다른 글
| 티스토리 마크다운 지원 (0) | 2019.04.04 |
|---|

전적으로 개발자의 코딩에 의존
상대적으로 메모리 낭비와 단일 쓰레드 성능 저하 발생
출처 : Rust 나무위키, https://lynlab.co.kr/blog/63
| 티스토리 마크다운 지원 (0) | 2019.04.04 |
|---|
크롬의 설정 파일을 변경하여 특정 확장자 파일을 자동 실행할 수 있습니다.
오피스, pdf 등의 파일을 바로 열고 싶은 업무 환경에서 사용하면 유용할 듯 합니다.
방법은 아래와 같습니다.
먼저 실행 중인 크롬 브라우저를 닫습니다.
cmd 창을 실행합니다.
아래 명령어를 그대로 실행합니다. 크롬 카나리를 사용하시는 분은 Chrome 대신 Chrome SxS 경로를 입력해야 합니다.
열린 편집창에서 download 부분을 찾아서 "extensions_to_open":"doc:docx:xls:xlsx:ppt:pptx:pdf" 를 추가해줍니다.
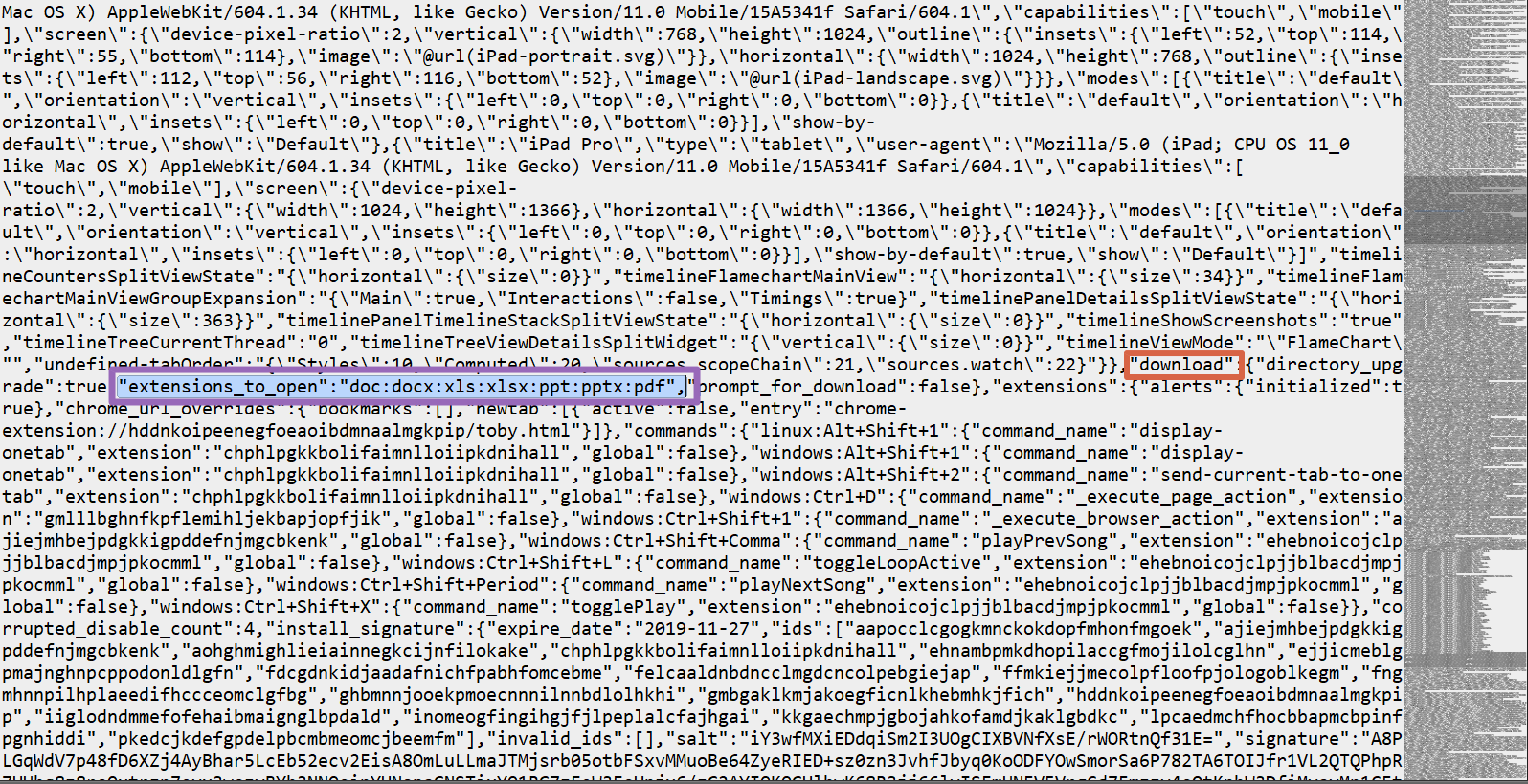
크롬을 실행하여 pdf, office 문서를 열어봅니다.

| Docker 내부 구조 (0) | 2020.05.14 |
|---|---|
| Docker Container 내에서 Docker Container 를 생성하기 (DooD 방식) (0) | 2019.06.26 |
| HyperledgerFabric 구축 (Kubernetes) (0) | 2019.01.23 |